
[ADSP] 3과목 2장 R 프로그래밍 기초
R 기초 -1
패키지
패키지 불러들이기
install.packages("AID")
AID 패키지 설치
***
패키지 도움말
library(help=AID)
다운로드 된 AID 패키지의 help 다큐먼트 보여줌
help(package=AID)
웹을 통해 AID 패키지의 다큐먼트 보여줌
***
프로그램 파일 실행
source("파일명")
스크립트로 프로그래밍 된 파일 실행하기
sink(file, append, split)
R 코드 실행 결과를 특정 파일에서 출력
file : 출력할 파일명
append : 파일에 결과를 덮어쓰거나 추가해서 출력(디폴트 값인 FALSE는 덮어쓰기)
split : 출력파일에만 출력하거나 콘솔창에 출력(디폴트 값인 FALSE는 파일에만 실행결과 출력)
pdf()
그래픽 출력을 pdf 파일로 지정
dev.off()
파일 닫기
배치모드 기능
배치파일 실행 명령
윈도우 도스창에서
$R CMD BATCH batch.R
Path 지정
‘내 컴퓨터’에 오른쪽 마우스 -> 속성 -> 고급시스템 설정 -> 환경변수 클릭 -> 변수명 path 클릭 -> R프로그램 실행파일 위치 추가 -> 저장
배치파일 실행
윈도우 창의 batch.R 실행파일이 있는 위치에서
R CMD BATCH batch.R
변수와 벡터 생성
R 데이터 유형과 객체
| 유형 | 모드 |
|---|---|
| 숫자(Number) | integer, double |
| 논리값(Logical) | True(T), False(F) |
| 문자(Character) | “a”,”abc” |
R 기초 - 2
기초 중에 기초
# 출력하기
print("a") # 한번에 하나의 객체
cat("a","b","c") # 여러 항목을 묶어서 연결된 결과로 출력
# 변수 목록보기
Is()
Is.str()
# 변수 삭제
rm(list=Is()) # 모든 변수를 삭제
# 벡터 생성
c()
# R 함수 정의
function(매개변수1, 매개변수2){
실행할 것
}
R 프로그램 소개
# 데이터 할당
a<-1
b=1
# 화면 프린트
a
print(b)
# 결합
x <- c(1,2,3,4) # 문자, 숫자, 논리값, 변수 상관없이 벡터 생성 가능
# 수열
1:5
9:-2 # 9에서 -2까지 역순
seq(from=0, to =20, by=2)
seq(from =0, to=20,length.out=5) # length.out으로 길이 제한
# 반복
rep(1,times=5)
rep(1:4,each=2) # 각각 2번씩 반복
# 문자 붙이기
C <- paste("a","b","c",sep="-")
C
paste(C,c("e","f")) # "a-b-c e" "a-b-c f"
paste(C,10,sep="") # "a-b-c10"
# 문자열 추출
substr("Bigdatasanghwa",1,4) # "Bigd"
# 논리값
a <- TRUE
a <- T
b <- FALSE
b <- F
# 논리 연산자
a == b # 같다
a != b # 같지않다
a < b # 작다
a <= b # 작거나 같다
a > b # 크다
a >= b # 크거나 같다
# 벡터의 원소 선택
x[1]
x[-1] # 제외하고자 하는 자리 인덱스
벡터의 연산
# []
a[1]
# $
a$coef
# ^
5^2 # 지수
# - + 부호
-3
+5
# :
1:10
# %any%
%/% # 나눗셈 몫
%% # 나눗셈 나머지
%*% # 행렬곱
# * /
3*5
3/5
# + -
3+5
3-5
# == != < <= > >= 비교
3==5
# ! 논리 부정
3!=5
# & 논리 and
TRUE & TRUE
# | 논리 OR
TRUE | FALSE
# ~ 식
lm(log(brain)~log(body),data = Animals)
# -> 오른쪽 대입
3 -> a
# = 대입(오른쪽을 왼쪽으로)
a = 3
# <- 대입
a <- 3
# 도움말
?lm
연산자 나열 순서는 연산자 우선순위 순서
벡터의 기초통계
#평균
mean(a)
#합계
sum(a)
# 중앙값
median(a)
# 로그
log(a)
# 표준편차
sd(a)
# 분산
var(a)
# 공분산
cov(a,b)
# 상관계수
cor(a,b)
# 변수의 길이 값
length(a)
R 프로그래밍시 주의할점
- 함수 불러오고 괄호 닫기
- 파일 경로에서 역슬래시 두번쓰기
- 역슬래시 두번쓰거나(\) 슬래시 한번써야함 (/)
- <- 사이 붙여쓰기
- 여러줄을 넘어서 식을 계속 이어갈때 (>) 쓰기
- == 대신 = 사용금지
- 괄호 잘쓰기
- 1:(n+1)을 1:n+1로 쓰면 안됨
- 패키지를 불러오고 libary()나 require() 수행
입력과 출력
# 키보드로 입력
c()
# 출력할 내용의 자리수 정의
print(pi, digits = 7)
cat(format(pi,digits=7),"\n")
options(digits=num)
# 파일에 출력
cat("출력할 내용", pi, file = "파일이름", append = T)
sink("파일이름")
# 파일 목록보기
list.files()
list.files(recursive = T, all.files=T)
# 파일위치 나타내기
c:/data/sample.txt
c:\\data\\sample.txt
# 고정자리수 데이터 파일 읽기
read.fwf("파일이름", widths=c(w1,w2))
# 테이블로 된 데이터 파일 읽기
read.table("파일이름", sep="구분자", stringsASFacter = F, na.strings=".", header = T)
# CSV 파일 읽기
read.csv("파일이름", header = T, as.is=T) # as.is=T는 텍스트를 요인으로 인식하지 말라는 뜻
# CSV 파일로 출력
write.csv(행렬 또는 데이터프레임,"파일 이름", row.names = F, col.names = F)
### 행이 변수명이 아닐경우 col.names = F
### 1열에 레코드 번호를 자동생성하지 않을경우 row.names = F
# 웹에서 데이터 파일 읽어올때
read.csv("http://www.hello.com/download/data.csv")
read.table("http://www.hello.com/download/data.csv")
# HTML에서 테이블 읽어올때
library(XML)
url <-"http://www.hello.com/download/table.html"
t <- readHTMLTable(url)
# 복잡한 구조의 파일읽기
lines <- readLines("a.txt",n=num)
token <- scan("a.txt", what=numeric(0)) # 토큰을 숫자로 해석
token <- scan("a.txt", what=list(v1=character(0),v2=numeric(0)))
token <- scan("a.txt", what=list(v1=character(0),v2=numeric(0), n=num,nlines=num,skip=num,na,strings=list))
데이터 구조와 데이터 프레임
벡터(Vector)
- 벡터들은 동질적이다
- 한 벡터의 모든 원소는 같은 자료형 또는 같은 모드를 가진다
- 벡터는 위치로 인덱스 된다
- v[2]는 v벡터의 2번째 원소다
- 벡터는 인덱스를 통해 여러 개의 원소로 구성된 하위 벡터를 반환할 수 있다
- V[c(2,3)]은 V벡터의 2번째, 3번째 원소로 구성된 하위 벡터이다
- 벡터 원소들은 이름을 가질 수 있다
- V <- c(10,20,30); names(V) <- c(“a”,”b”,”c”)
리스트(Lists)
- 리스트는 이질적이다
- 여러 자료형의 원소 포함 가능
- 리스트는 위치로 인덱스 된다
- L[[2]]는 L리스트의 2번째 원소다
- 리스트는 하위 리스트를 추출할 수 있다
- L[c(2,3)]은 L리스트의 2번째, 3번째 원소로 구성된 하위 리스트이다
- 리스트의 원소들은 이름을 가질 수 있다
- L[[“Moe”]]와 L$Moe는 둘다 “Moe”라는 이름의 원소를 지칭한다
R에서의 자료형태
| 객체 | 예시 | 모드 |
|---|---|---|
| 숫자 | 3.1415 | 수치형 |
| 숫자 벡터 | c(2,3,4,5.5) | 수치형 |
| 문자열 | “Tom” | 문자형 |
| 문자열 벡터 | c(“a”,”b”,”c”) | 문자형 |
| 요인 | factor(c(“A”,”B”,”C”)) | 수치형 |
| 리스트 | list(“a”,”b”,”c”) | 리스트 |
| 데이터 프레임 | data.frame(x=1:3,y=c(“a”,”b”,”c”)) | 리스트 |
| 함수 | 함수 |
데이터 프레임
- 데이터 프레임의 리스트의 원소는 벡터 또는 요인이다
- 벡터와 요인은 데이터 프레임의 열이다
- 벡터와 요인은 동일한 길이다
- 표 형태의 데이터 구조
- 열에는 이름이 있어야한다
- 데이터 프레임의 원소에 대한 접근방법
b[1] ; b["empno"]
b[[i]] ; b [["empno"]]
b$empno
단일값
R에서는 원소가 하나인 벡터로 인식
행렬
R에서는 차원을 가진 벡터로 인식
a<-1:9
dim(a)<-c(3,3)
배열
행렬에 3차원 또는 n차원까지 확장된 형태
b <-1:12
dim(b) <- c(2,3,2)
요인(factor)
- 벡터처럼 생겼지만 벡터에 있는 고유값의 정보를 얻어내는데, 이 고유값들을 요인의 수준(level)이라고 한다
- 범주형 변수, 집단분류에 사용
벡터, 리스트, 행렬 다루기
재활용 규칙(Recycling Rule): 길이가 서로 다른 두 벡터에 대해 연산을 할 때, R은 짧은 벡터의 처음으로 돌아가 연산이 끝날때까지 원소들을 재활용한다.
# 벡터에 데이터 추가
v <- c(v, newItems)
v[length(v)+1] <- newItems
# 벡터에 데이터 삽입
append(vec, newvalues, after = n)
# 요인 생성
f <- factor(v) # v:문자열 또는 정수 벡터
f <- factor(v, levels)
# 여러 벡터를 합쳐 하나의 벡터와 요인으로 만들기
comb <- stack(list(v1=v1,v2=v2,v3=v3))
# 벡터 내 값 조회
백터[c(1,3,5,7)]
벡터[-c(2,4)] # 2,4 번째 값 제외하고 조회
# 리스트
list(숫자, 문자, 함수)
# 리스트 생성하기
L <- list(x,y,z)
L <- list(valuename1 = data, valuename2 = data, valuename3 = data)
L <- list(valuename1 = vec, valuename2 = vec, valuename3 = vec)
# 리스트 원소 선택
L[[n]]
L[[c(n1,n2,...,nk)]]
# 이름으로 리스트 원소 선택
L[["name"]]
L$name
# 리스트에서 원소제거
L[["name"]] <- NULL
# NULL 원소를 리스트에서 제거
L[sapply(L,is.null)] <- NULL
L[L==o] <- NULL
L[is.na(L)] <- NULL
# 행렬
matrix(data, 행수, 열수)
a <- matrix(data,2,3)
d <- matrix(0,4,5)
e <- matrix(1:20,4,5)
# 차원
dim(행렬)
dim(e)
# 대각
diag(행렬)
diag(e)
# 전차
t(행렬)
t(e)
# 역
solve(matrix)
# 행렬의 곱
행렬 %*% t(행렬)
e %*% t(e)
# 행 이름 부여
rownames(e) <- c("행이름1","행이름2","행이름3","행이름4")
# 열 이름 부여
colnames(e) <- c("열이름1", "열이름2", "열이름3", "열이름4", "열이름5")
# 행렬의 연산 +,-
e+e
e-e
e+1
e-1
# 행렬의 연산 *
e %*% e
e*3
# 행렬에서 행, 열 선택
vec <- matrix[1,]
vec <- matrix[,3]
실제 e 값 출력 결과
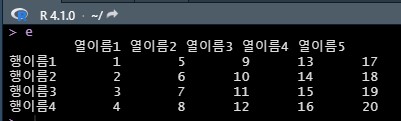
데이터 프레임
# 데이터프레임
data.frame(벡터,벡터,벡터)
# 레코드 생성
new <- data.frame(a=1,b=2,c=3,d="a")
# 열 데이터로 데이터프레임 만들기
dtm <- data.frame(v1,v2,v3,f1,f2)
dfm <- as.data.frame(list.of.vectors)
# 데이터셋 행결합
rbind(dfrm1, dfrm2)
newdata <- rbind(newdata, new) # 데이터프레임을 행으로 결합
# 데이터셋 열결합
cbind(dfrm1, dfrm2)
cbind(newdata, newcol) # 데이터프레임을 열로 결합
# 데이터 프레임 할당
N=1000000
dtfm <- data.frame(dosage=numeric(N))
lab = character(N), respones = numeric(N)
# 데이터 프레임 조회
dfrm[dfrm$gender = "m"]
dfrm[dfrm$변수1 > 4 & dfrm$변수2 > 5, c[변수3, 변수4]] # 조건을 만족하는 변수3, 변수4만 조회
dfrm[grep("문자", dfrm$변수1, ignore.case = T), c("변수2","변수3")] # 변수1내 "문자"가 들어있는 케이스들의 변수2,3값을 조회
# 데이터셋 조회
subset(dfrm, select=변수, subset=변수>조건) # 조건에 맞는 변수셋 조회
# 데이터 선택
lst1[[2]], lst1[2], lst1[2,], lst1[,2]
lst1[["name"]], lst1$name,
lst1[c("name1","name2")]
# 데이터 병합
merge(df1,df2,by="둘의 공통 열 이름", all = T)
# 열 이름 조회
colnames(변수)
# 행, 열 선택
subset(dfm, select= 열이름)
subset(dfm, select= c(열이름1,열이름2,열이름3,열이름4))
subset(dfm, select= 열이름, subset= (조건))
# 이름으로 열 제거
subset(dfm, select= "열이름")
# 열 이름 바꾸기
colnames(dfm) <- newnames
# NA있는 행 삭제
NA_cleaning <- na.omit(dfm)
자료형 데이터 구조 변환
# 데이터 프레임의 내용에 쉽게 접근
with(dfm, expr)
attach(e)
detach(e)
# 자료형 반환
as.character()
as.complex()
as.numeric()
as.double()
as.integer()
as.logical()
# 데이터 구조 변환
as.data.frame()
as.list()
as.matrix()
as.vector()
데이터 구조 변경
# 벡터 -> 리스트
as.list(vec)
# 벡터 -> 행렬
cbind(vec) as.matrix(vec) # 1열짜리
rbind(vec) # 1행짜리
matrix(vec,n,m) # n x m 행렬
# 벡터 -> 데이터 프레임
as.data.frame(vec) # 1열짜리
as.data.frame(rbind(vec)) # 1행짜리
# 리스트 -> 벡터
unlist(lst)
# 리스트 -> 행렬
as.matrix(lst) # 1열짜리
as.matrix(rbind(lst)) # 1행짜리
matrix(lst,n,m) # n x m
# 리스트 -> 데이터 프레임
as.data.frame(lst) # 목록 원소들이 데이터의 열
rbind(obs[[1]], obs[[2]]) # 리스트 원소들이 데이터의 행
# 행렬 -> 벡터
as.vector(mat)
# 행렬 -> 리스트
as.list(mat)
# 행렬 -> 데이터 프레임
as.data.frame(mat)
# 데이터 프레임 -> 벡터
dfm[[1]] dfm[,1] # 1열짜리
dfm[1,] # 1행짜리
# 데이터 프레임 -> 리스트
as.list(dfm)
# 데이터 프레임 -> 행렬
as.matrix(dfm)
벡터 기본연산
# 벡터 연산
벡터1 + 벡터2
벡터1 - 벡터2
벡터1 * 벡터2
벡터1 ^ 벡터2 # 승수
# 함수
sapply(변수, 연산함수)
# 파일저장
write.csv(변수이름, "파일이름.csv")
save(변수이름, file = "파일이름.Rdata")
# 파일 읽기
read.csv("파일이름.csv")
# 파일 불러오기
load("파일.R")
source("파일.R")
# 데이터 삭제
rm(변수)
rm(list = Is(all=TRUE)) # 모든 변수를 메모리에서 삭제
그 외에 간단한 함수
# 데이터 불러오기
data()
data(데이터셋)
# 데이터셋요약
summary(데이터셋)
# 데이터셋 조회
head(데이터셋) # 6개 까지
# 패키지 설치
install.packages("패키지명")
# 작업종료
q()
# 워킹디렉토리 지정
setwd("~/")
데이터 변형
주요코드
# 요인으로 집단 정의
v<-c(24,23,52,46,75,25)
f<-factor(c("A","A","B","B","C","A"))
# 벡터를 여러집단으로 분할 (벡터길이 같으면됨)
groups <-split(v,f)
groups <- unstack(data.frame(v,f))
# 데이터 프레임을 여러집단으로 분할
library(MASS)
sp <- split(Cars93$MPG.city, Cars93$Origin)
median(sp[[1]])
# 리스트의 각 원소에 함수적용
lapply(결과를 리스트 형태로 반환)
sapply(결과를 벡터 또는 행렬로 반환)
# 행렬에 함수 적용
m <- apply(mat,1,func)
# 데이터 프레임에 함수적용
lapply(dfm, func)
sapply(dfm, func)
apply(dfm, func)
# 대용량 데이터의 함수
cors <- sapply(dfm, cor, y=targetVariabele) # 데이터 프레임에서 타겟변수 정하고, 타겟변수와 상관계수 구함
mask <-(rank(-abs(cors))<=10) # 상관계수가 높은 상위 10개의 변수를 입력변수로 선정
best.pred<-dfm[,mask]
lm(targetVariabele~bes.pred) # 타겟변수와 입력변수로 다중회귀분석 실시
# 집단별 함수 적용
taaply(vec,factor,func)
# 행집단 함수 적용
by(dfm, factor, func)
# 벡터, 리스트들 함수적용
mapply(factor, vec1, vec2, vec3)
문자열 날짜 다루기
# 문자열 길이
nchar("단어")
# 문자열 연결
paste("단어1","단어2",sep="-")
paste("나","loves me",collapse=", and")
# 하위 문자열 추출
substr("hello", 1,4)
# 구분자로 문자열 추출
strsplit(문자열, 구분자)
# 하위 문자열 대체
sub(old, new, string)
gsub(old, new, string)
# 쌍별 조합
문자열1 = "난 상화"
문자열2 = "넌 누구"
mat <- outer(문자열1, 문자열2, paste, sep="")
mat
# 날짜 변환
Sys.Date() # 현재 날짜
as.Date(x) # 날짜 객체로
format(Sys.Date(),format = "%m/%d/%y" )
# 날짜 조회
format(Sys.Date(), '%a') # 요일
format(Sys.Date(), '%b') # 월 숫자
format(Sys.Date(), '%B') # ~월
format(Sys.Date(), '%d') # 두자리숫자 일
format(Sys.Date(), '%m') # 두자리숫자 월
format(Sys.Date(), '%y') # 두자리숫자 연도
format(Sys.Date(), '%Y') # 네자리숫자 연도
# 날짜 일부 추출
d <- as.Date("2000-02-28")
p <- as.POSIXlt(d)
p$yday
start <- as.Date("2000-2-2")
end <- as.Date("2000-2-28")
seq(from = start, to=end, by=1)
댓글남기기