
[ADSP] 3과목 3장 데이터 마트
데이터 변경 및 요약
데이터 마트
데이터 웨어하우스와 사용자 사이의 중간층에 위치한 것
요약변수
- 수집된 정보를 분석에 맞게 종합한 변수
- 데이터마트에서 가장 기본적인 변수로 총 구매 금액, 금액, 횟수, 구매여부 등 데이터 분석을 위해 만들어지는 변수
- 재활용성 높음
- 연속형 변수를 그룹핑해 사용하는 것이 좋음
- 요약변수 예시
- 기간별 구매 금액, 횟수 여부
- 위클리 쇼퍼
- 상품별 구매 금액, 회수 여부
- 상품별 구매 순서
- 유통 채널별 구매 금액
- 단어 빈도
- 초기 행동변수
- 결측값과 이상값 처리
- 연속형 변수의 구간화
파생변수
- 특정조건을 만족하거나 특정 함수에 의해 값을 만들어 의미를 부여한 변수
- 주관적일 수 있으므로 논리적 타당성을 갖추어 개발해야함
- 세분화, 고객행동 예측, 캠페인 반응 예측
- 파생변수 예시
- 근무시간 구매자수
- 주 구매 매장 변수
- 주 활동 지역 변수
- 주 구매상품 변수
- 구매상품 다양성 변수
- 선호하는 가격대 변수
- 시즌 선호고객 변수
- 라이프 스테이지 변수
- 라이프스타일 변수
- 행사민감 변수
- 휴면가망 변수
- 최대가치 변수
- 최적 통화 시간
reshape의 활용
reshape 패키지에는 melt()와 cast()라는 2개의 핵심함수 있음
melt() : 원데이터 형태로 만드는 함수, 쉬운 casting을 위해 적당한 형태로 만들어줌
melt(data,id=...)
melt(airquality, id=c("Month", "Day"), na.rm=T)
cast() : 요약 형태로 만드는 함수, 데이터를 원하는 형태로 계산 또는 변형 시켜주는 함수
cast(data, formula=...~ variable, fun)
cast(aqm, Day ~ Month ~ variable)
sqldf를 이용한 데이터 분석
sqldf는 R에서 sql의 명령어를 사용할 수 있게 해줌
sql과 sqldf의 차이
select * from [data frame] #SQL
sqldf("select * from [data frame]")
select * from [data frame] numrows 10 # SQL
sqldf("select * from [data frame] limit 10")
select * from [data frame] where [col] = 'char%' # SQL
sqldf("select * from [data frame] where [col] like 'char%' ")
R 문법을 sqldf 문법으로 적어보기
head([df])
sqldf("select * from [df] limit 6")
subset([df], grep1("qn%", [col]))
sqldf("select * from [df] where [col] like 'qn%' ")
subset([df], [col] %in% c("BF","HF"))
sqldf("select * from [df] where [col] in('BF','HF')")
rbind([df1], [df2])
sqldf("select * from [df1] union all select * from [df2]")
merge([df1], [df2])
sqldf("select * from [df1], [df2]")
df[order([df]$[col], decreasing=T),]
sqldf("select * from [df] order by [col] desc")
plyr을 이용한 데이터 분석
plyr은 apply 함수에 기반해 데이터와 출력변수를 동시에 배열로 치환하여 처리하는 패키지
split-apply-combine
데이터를 분리하고 처리한 다음, 다시 결합하는 데이터 처리기능 제공
| array | data frame | list | nothing | |
|---|---|---|---|---|
| array | aaply | adply | alply | a_ply |
| data frame | daply | ddply | dlply | d_ply |
| list | laply | ldply | llply | l_ply |
| n replicates | raply | rdply | rlply | r_ply |
| function arguments | maply | mdply | mlply | m_ply |
데이터 테이블
- data.table 패키지는 R에서 가장 많이 사용하는 데이터 핸들링 패키지
- 큰 데이터를 탐색, 연산, 병합 하는데 아주 유용
- 기존 data.frame 보다 월등히 빠름
- 특정 컬럼을 key 값으로 색인을 지정한 후 데이터 처리
- 빠른 그루핑과 ordering, 짧은 문장 지원 측면에서 데이터 프레임보다 유용
데이터 가공
Data Exploration
- head(데이터셋), tail(데이터셋)
- 시작 또는 마지막 6개 record만 조회
- summary(데이터셋)
- 수치형변수 : 최대값, 최소값, 평균, 1사분위수, 2사분위수(중앙값), 3사분위수
- 명목형변수 : 명몫값, 데이터 개수
변수 중요도
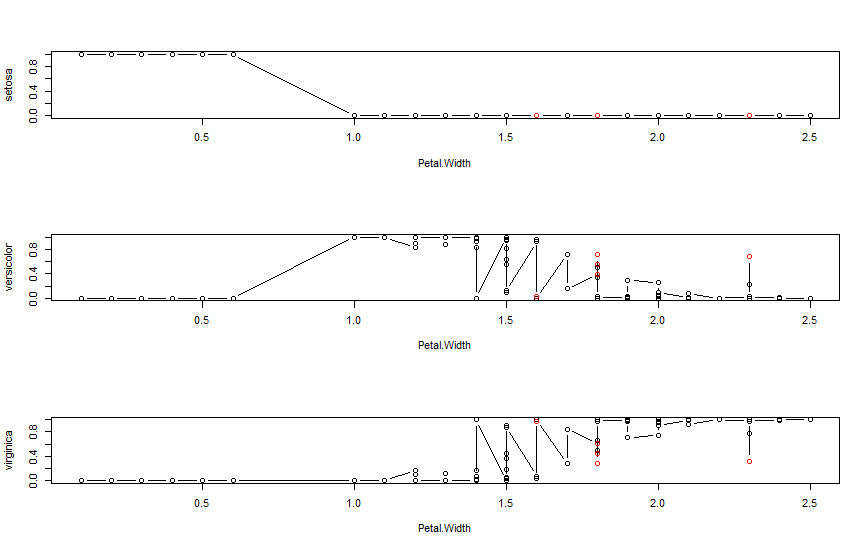
klaR 패키지
- 특정 변수가 주어졌을때 클래스가 어떻게 분류되는지에 대한 에러율 계산, 그래픽으로 결과보여줌
- greedly.wilks()
- 세분화를 위한 stepwise forward 변수선택을 위한 패키지
- 종속변수에 가장 영향력을 미치는 변수를 wilks lambda를 활용하여 변수의 중요도 정리
- Wilk’s Lambda = 집단내분산/총분산
- klaR 예제
install.packages("klaR")
library("klaR")
iris2 <- iris[,c(1,3,5)]
head(iris2)
plineplot(Species ~ ., data = iris2, method = "lda", x=iris[,4], xlab = "Petal.Width")
변수의 구간화
- 연속형 변수를 분석 목적에 맞게 활용하기 위해 구간화
- 구간을 5개로 나누는 것이 보통
구간화 방법
- binning
- 신용평가모형의 개발에서 연속형 변수를 범주형 변수로 구간화하는데 자주 활용되고 있는 방법
- 연속형 변수를 오름차순 정렬한 후 동일한 개수의 레코드를 50개의 bin에 나누어 담고 bin의 부실율을 기준으로 병합하면서 최종 5~7개의 bin으로 부실율의 역전이 생기지 않게 합치면서 구간화
- 의사결정나무
- 세분화 또는 예측에 활용되는 의사결정나무 모형을 사용하여 입력변수를 구간화 할 수 있음
- 연속변수가 반복적으로 선택될 경우, 각각의 분리 기준값으로 연속형 변수 구간화 가능
기초 분석 및 데이터 관리
데이터 EDA(탐색적 자료 분석)
- 데이터의 분석에 앞서 전체적으로 데이터 특징 파악
- summary()를 이용하여 데이터의 기초통계량 확인
결측값 인식
- 결측값은 NA, 99999999, ‘ ‘, Unknown, Not Answer 등으로 표현
- 결측값 자체의 의미가 있는 경우도 있음
- na.rm을 이용하면 NA를 제거할 수 있음
> x <- c(1,2,3,NA)
> mean(x)
[1] NA
> mean(x,na.rm=T)
[1] 2
결측값 처리 방법
단순 대치법(Single Imputation)
- completes analysis
- 결측값이 존재하는 레코드 삭제
- 평균대치법(Mean Imputation)
- 데이터의 평균으로 대치
- 비조건부 평균 대치법 : 관측데이터의 평균으로 대치
- 조건부 평균 대치법(regression imputation) : 회귀분석을 활용한 대치법
- 단순확률 대치법(Single Stochastic Imputation)
- 평균대치법에서 추정량 표준 오차의 과소 추정문제를 보안하고자 고안
- Hot-deck 방법, nearest neighbor 방법 등
다중 대치법(Multiple Imputation)
- 단순대치법을 한번하지 않고 m번의 대치를 통해 m개의 가상적 완전자료 만드는 방법
- 1단계 : 대치(imputation step)
- 2단계 : 분석(Analysis step)
- 3단계 : 결합(combination step)
R에서 결측값 처리
| 함수 | 내용 |
|---|---|
| complete.cases() | 데이터내 레코드에 결측값이 있으면 FALSE, 없으면 TRUE로 반환 |
| is.na() | 결측값을 NA로 인식하여 결측값이 있으면 TRUE, 없으면 FALSE로 반환 |
| DMwR 패키지의 centralImputation() | NA 값에 가운데 값(central value)로 대치, 숫자는 중위수, 요인(factor)은 최빈값으로 대치 |
| DMwR 패키지의 knnImputation() | NA 값을 k최근 이웃 분류 알고리즘을 사용하여 대치, k개 주변 이웃까지의 거리를 고려하여 가중 평균한 값을 사용 |
| Amelia 패키지의 amelia() | randomForest 패키지의 rfImpute()함수를 활용하여 NA 결측값을 대치한 후 알고리즘 적용 |
이상값(Outlier) 인식과 처리
이상값이란?
- 의도하지 않게 잘못 입력(bad data)
- 의도하지 않게 입력, 분석 목적에 부합되지 않아 제거해야 하는 경우(bad data)
- 의도하지 않은 현상이지만 분석에 포함해야 하는 경우
- 의도된 이상값(fraud, 불량)인 경우
이상값의 인식 방법
- ESD(Extreme Studentize Deviation)
- 평균으로부터 3표준편차 떨어진 값 (각 0.15%)
- 기하평균 - 2.5 x 표준편차 < data < 기하평균 + 2.5 x 표준편차
- 사분위수 이용하여 제거(상자 그림의 outer fence 밖에 있는 값 제거)
- 이상값 정의 : Q1 - 1.5(Q3-Q1) < data < Q1 + 1.5(Q3-Q1)
극단값 절단(trimming) 방법
- 기하평균을 이용한 제거
- geo_mean
- 하단, 상단 % 이용한 제거
- 10% 절단(상하위 5%에 해당되는 데이터 제거)
극단값 조정(winsorizing) 방법
- 상한값과 하한값을 벗어나는 값들을 하한, 상한값으로 바꾸어 활용
- 극단값 절단 방법보다 데이터 손실율도 적고, 설명력도 높아짐
댓글남기기