
[공빅데 프로젝트] Google 뉴스 기사 제목 크롤링
Google 뉴스 기사 크롤링
프로젝트 개요에서 본 것처럼 워드클라우드를 만들기위해 먼저 ‘스마트 횡단보도’에 대한 뉴스기사 제목과 제목 밑에 짤막한 내용을 긁어올것이다 !
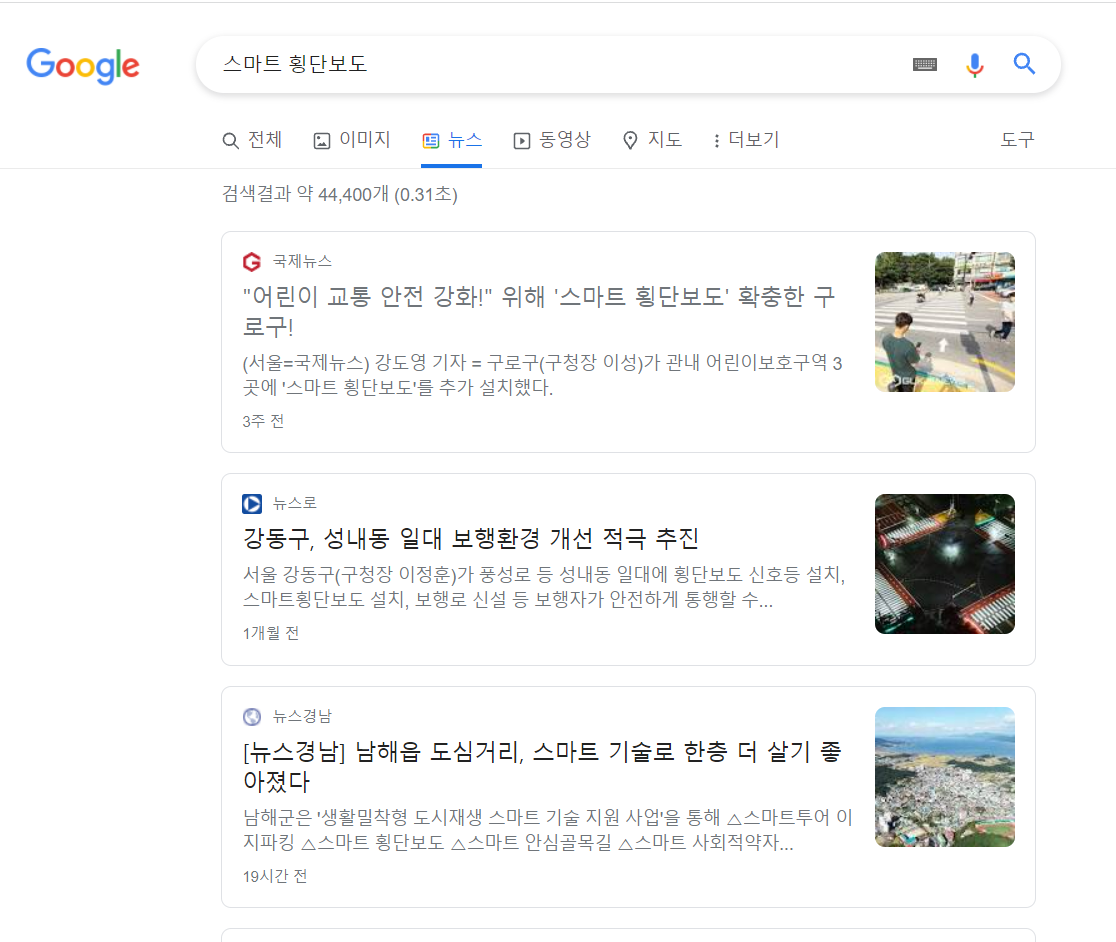
여기 보이는 것 처럼 제목이랑 밑에 짧은 내용만 긁어오는거라 크롤링은 생각보다 어렵지 않다 ㅎ 그럼 지금 부터 시작 !
Link 알아내기
우리가 무언가를 긁어오려면 당연히! 링크를 알아야할 것이다. 구글에 ‘스마트 횡단보도’를 검색하고 URL을 살펴보자.
첫번째 페이지와 두번째 페이지의 URL이다. 차이점을 찾았나요?!?
정답은 가운데 & 사이로 연결되어있는 start = 에 있다. 페이지별로 첫 번째 페이지는 start = 0, 두 번째 페이지는 start = 10, 세 번째 페이지는 start = 20 …. 이렇게 URL이 구성되어있다.
그렇다면 ! 우리는 생각할 수 있다 ! 페이지를 쭉쭉 넘기며 데이터를 받아오기위해서는 가운데 start = (이 숫자들)만 바꿔주면 되겠구나 ! 그렇게 URL 목록을 만들어 볼 것이다.
Link가 담긴 txt파일 만들기
우선 크롤링과 파일 만드는데 필요한 패키지와 모듈을 import 해주자
import requests as rq
import bs4
import time
import pandas as pd
다음 가운데 숫자 두자리를 제외한 반복되는 주소를 각각 base변수와 url 변수에 저장해 줄것이다.
base = "https://www.google.com/search?q=%EC%8A%A4%EB%A7%88%ED%8A%B8+%ED%9A%A1%EB%8B%A8%EB%B3%B4%EB%8F%84&tbm=nws&ei=e_FcYa32Gsbm-AbzwKuIAQ&start="
url = "&sa=N&ved=2ahUKEwjtn-edx7TzAhVGM94KHXPgChE4ChDy0wN6BAgBEDU&biw=1536&bih=754&dpr=1.25"
이렇게 되면 base + 중간 숫자 + url을 하면 우리가 원하는 Link가 될 것이다. 총 22페이지까지 링크를 완성시켜서 ‘스마트 횡단보도(구글).txt’라는 파일에 저장해보자.
f = open("스마트 횡단보도(구글).txt","w",encoding = 'utf-8')
for i in range(0,22,1):
page = str(i) +'0' # 페이지수를 바꿔주는 부분 start=0, start=10,,,,
link = base + page + url
print(link)
f.write(link)
f.write('\n') # enter
time.sleep(1)
print("end") #Link Write를 완료하면 end 출력
f.close() #텍스트파일 닫기
이 작업을 완료하게 되면 아래와 같이 출력되고, 그 내용들이 ‘스마트 횡단보도(구글).txt’파일에 저장된다.


txt에서 Link 읽어오기
저장된 txt파일로부터 링크를 읽어서 link_list라는 변수에 저장하려고 한다. 이건 단순하게 파일을 읽어오기만 하면된다.
f = open("스마트 횡단보도(구글).txt","r",encoding ="utf-8")
for link_list in f:
link_list = f.readlines()
len(link_list) #길이확인
HTML 확인
링크를 알았으면 우리는 그 페이지 안에서 가져오고 싶은것이 어디에 있는지 확인해야한다. 확인하는 방법은 그렇게 어렵지 않다. 궁금한 곳에 마우스를 가져다대고 오른쪽 마우스를 클릭해보면 ‘검사’라는 것이 있을 것이다. 그것을 누르면 아래 창처럼 나오게 된다.
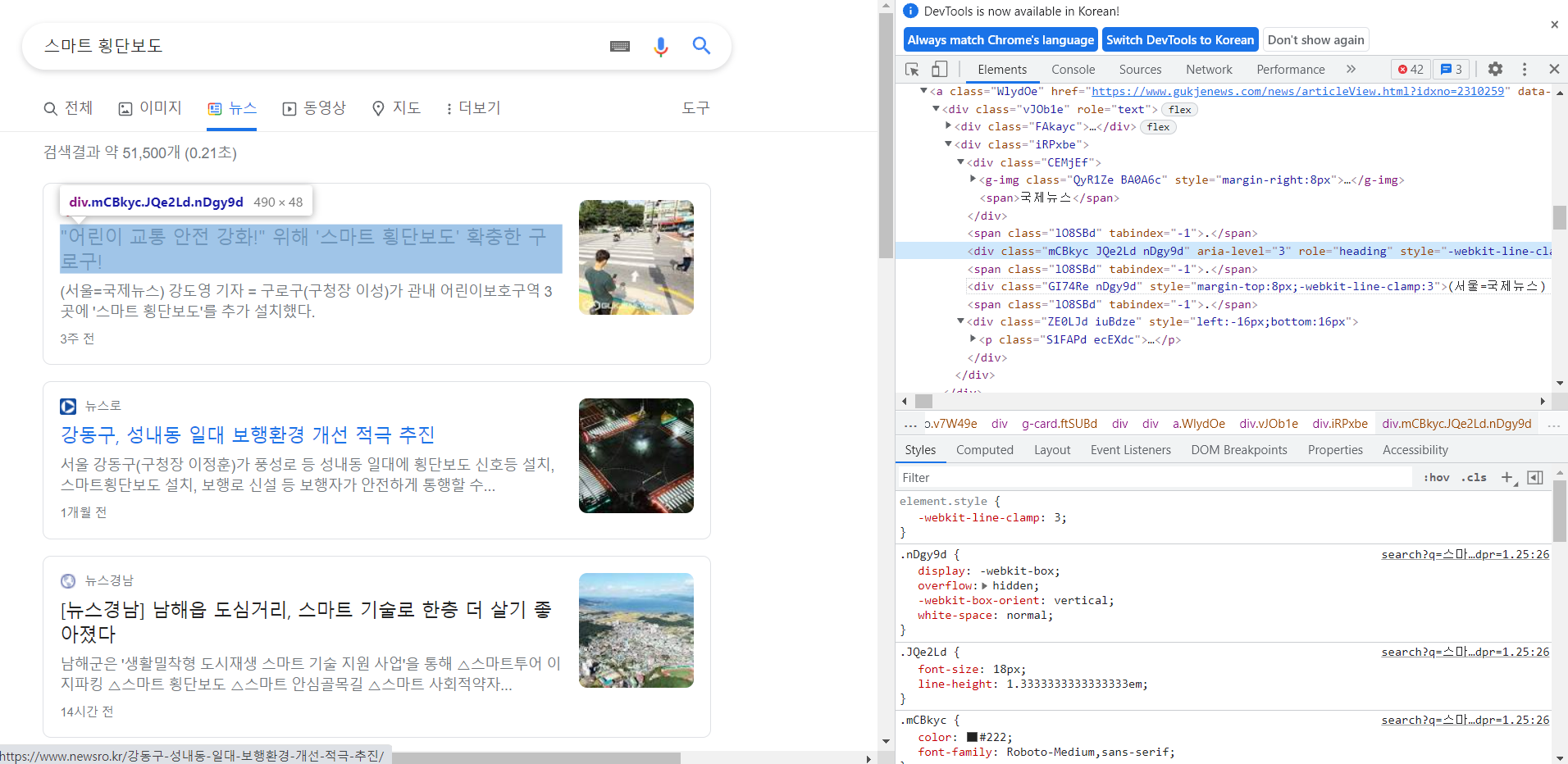
오른쪽에 보이는 것을 자세히 봐보자.

우리가 가져오고싶은 제목과 내용이 담겨있는 class가 보일 것이다.
제목은 div class=”mCBkyc JQe2Ld nDgy9d”에 내용은 div class=”GI74Re nDgy9d”에 저장되어있는 것을 확인할 수 있다. 쉽게 설명해서 한 페이지에 각 뉴스 제목들은 class=”mCBkyc JQe2Ld nDgy9d”에 저장되어있고, 아래에 짧은 내용들은 class=”GI74Re nDgy9d”에 저장되어있는 것이다. 따라서 페이지 하나를 긁어올때 저 class에 있는 애들을 다 긁어오세요~ 하면 우리가 원하는 내용들만 골라올 수 있을 것이다.
크롤링
우리는 bs4를 이용하여 크롤링을 진행할 것이다. 긁어온 내용들의 text를 데이터 프레임에 추가하는 방식으로 제목과 내용을 담은 데이터프레임을 만드는 것이 우리의 목적이다.
우선 제목과 내용을 담을 데이터 프레임을 만들어준다.
col = ["제목","내용"]
df = pd.DataFrame(index = range(0,0), columns = col)
다음 크롤링을 하여 저 df에 내용을 추가할 것이다.
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
#사람이 아닌 컴퓨터가 크롤링을할때 서버에서 차단하는 경우가 있음
#따라서 유저인것을 알려주기 위해 유저정보 입력
for i in range(0,len(link_list),1):
newsp = link_list[i]
res = rq.get(newsp, headers = headers)
soup = bs4.BeautifulSoup(res.text, 'html.parser')
title = soup.find_all("div", class_ = "mCBkyc JQe2Ld nDgy9d")
content = soup.find_all("div", class_ = "GI74Re nDgy9d")
for j in range(0, len(title),1):
title_text = title[j].text
content_text = content[j].text
info = [[title_text,content_text]]
df_append = pd.DataFrame(info, columns = col)
df = df.append(df_append, ignore_index = True)
time.sleep(1)
이렇게 진행하면 df에 우리가 원하는 제목들과 내용이 잘 들어갔을 것이다. 실제로 df를 표출해보면 아래와 같이 출력된다.

데이터프레임 xlsx파일로 저장
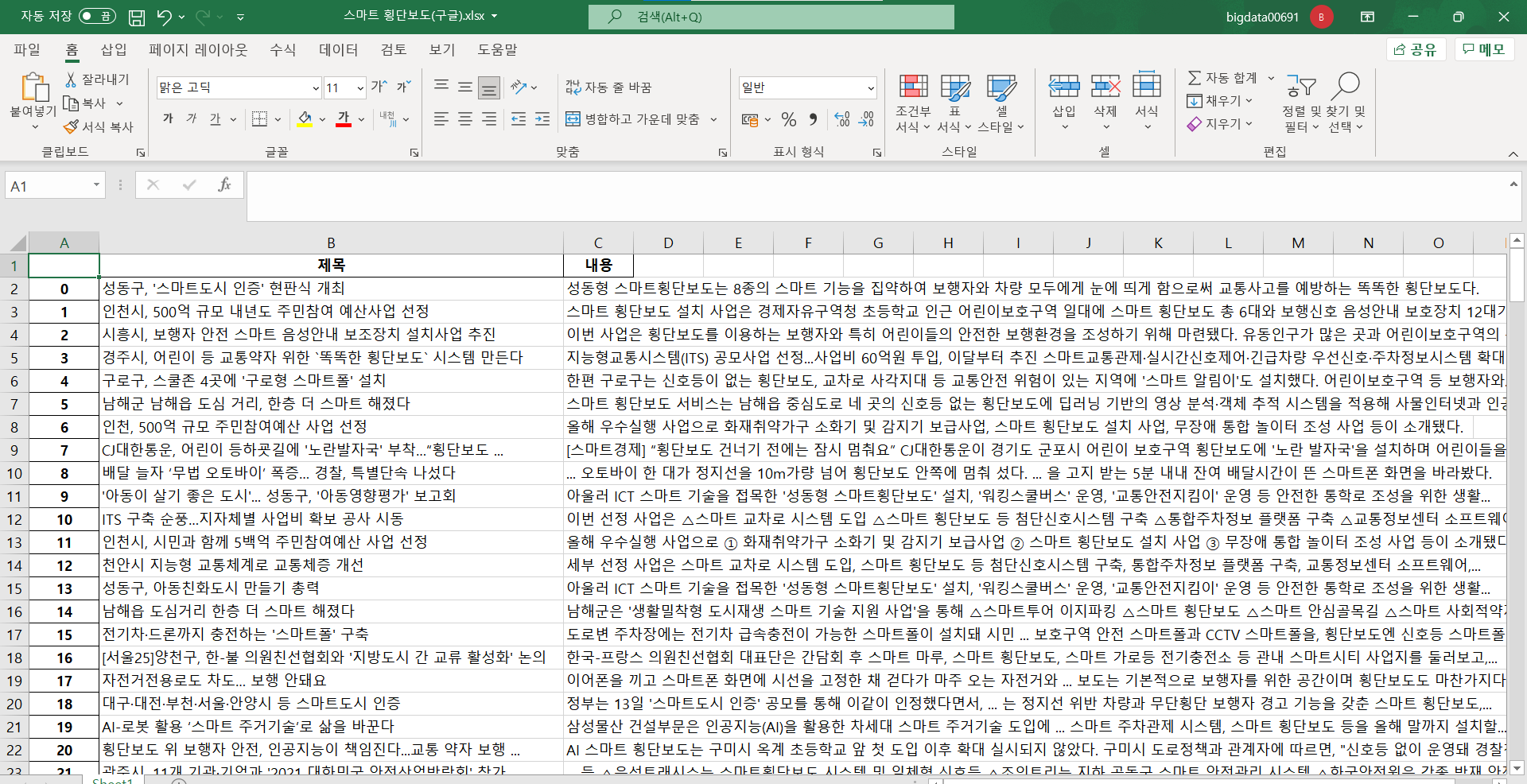
우리는 얻어온 데이터프레임을 ‘스마트 횡단보도(구글).xlsx’라는 엑셀파일로 저장할 것이다. 코드는 간단하다.
df.to_excel("스마트 횡단보도(구글).xlsx",encoding = 'utf-8')
아래와 같이 파일로 잘 저장된 것을 볼 수 있다.
전체코드 및 마무리
사실 엄청 어려운 것은 아니지만 크롤링은 하고나면 나름 뿌듯하다. 이제 이 녀석들로 워드클라우드를 만들어야 한다..! comming soon…
댓글남기기